하나의 영어단어를 입력했을 때 그 단어와 연관된, 함께 많이 사용이 되는 단어들을 찾기 위해 인공지능을 활용했다. 연관어를 찾는 단계는 다음과 같다.
입력 단어가 A라고 할 때.
1) 구글 검색창에 단어 A를 입력했을 때 나타나는 뉴스기사들의 제목과 본문 내용 일부를 페이지 1쪽부터 10쪽까지 탐색하며 가져온다.
2) 가져온 내용들을 전처리하여 인공지능이 학습할 수 있는 형태로 만든다.
3) word2vec 모델에 학습데이터를 넣어 연관어를 출력받는다.
즉, 단어를 검색할 때마다 그 단어에 맞는 학습데이터를 만들어서 연관어를 찾아내는 것이다. 매번 새롭게 탐색해야 해서 비효율적이지만 단어의 의미가 변화되거나 사회적으로 다른 의미로써 쓰이는 등 연관어가 바뀔 수 있는 경우에는 효과적이라고 볼 수 있다.

일단 연관어를 탐색할 단어를 입력 받는다.

크롤링을 위해 필요한 패키지와 라이브러리를 받아온다.

뉴스 제목을 추출하는 함수다. 구글 뉴스에서 개발자 모드를 켜보면 전체 뉴스 내용은 class명이 "v7W49e"인 div로 감싸져있다. 해당 div를 포함하여 그 내부에 있는 코드를 div_title에 저장한다.
그 중에서도 뉴스 제목은 class명이 "mCBkyc"인 div로 감싸져 있는데, 제목이 포함된 div 코드를 받아온 뒤 ger_text()를 이용해 제목 부분만 추출한다. 그렇게 추출한 제목을 result_title이라는 리스트에 모두 저장하여 반환한다.

뉴스 본문 내용을 가져오는 코드이다. 방법은 제목을 가져올 때와 같다. 지금 생각해보니 제목과 본문을 가져오는 함수를 굳이 따로 둘 필요가 있었나 싶다. 나중에 합쳐봐야겠다

구글 뉴스의 1쪽부터 10쪽까지를 탐색한다고 했는데, 처음 들어가면 1쪽으로 접속되므로 2~10쪽에 접근하려면 링크들이 필요하다. 제목과 본문을 가져오는 방법과 유사한데, 위에서는 get_text()로 태그의 내용을 가져온 것과 달리 여기서는 ['href']로 링크 부분을 가져온다.

위에서 가져온 각 페이지별 링크를 받아 제목과 본문을 추출하도록 하는 함수이다. main 함수에서 crawling_href 함수를 호출해 링크를 받은 뒤, 그 링그를 data_setting 함수의 매개변수로 넘겨준다.
custom_header = { 'referer' : 'https://www.google.com/', 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36' }
custon_header 부분은... 잘 모르겠다. 크롤링 하려면 적어줘야 하는 것 같다.
아래에 url은 크롤링을 할 주소를 적어주고, request 패키지를 이용하여 http 요청을 보낸다. 그리고 BeautifulSoup을 이용하여 html 코드를 받아온다.

메인 함수. 제목과 본문 텍스트를 다 받아오면 train_set이라는 리스트에 모두 저장한다.

이제 여기서부터 전처리가 시작된다. 이 부분은 전처리를 하기 전 필요한 라이브러리를 다운 받는 단계이다. 불용어, 특수문자를 제거하기 위해 사용된다.

원래 문장 형태였던 데이터를 단어 형태로 자르고, a, an, is 등 의미 없는 단어와 특수문자를 제거한다. 같은 문장에 포함되었던 단어는 같은 리스트에 들어가게 된다.
clean_data = [[x.lower() for x in each.translate(translator).split() if x.lower() not in stop_words] for each in content.split('.')]

전처리 된 데이터 중에서 빈 리스트를 제거해주는 작업이다.

이제 전처리 된 학습데이터를 word2vec 모델에 학습시킨다.
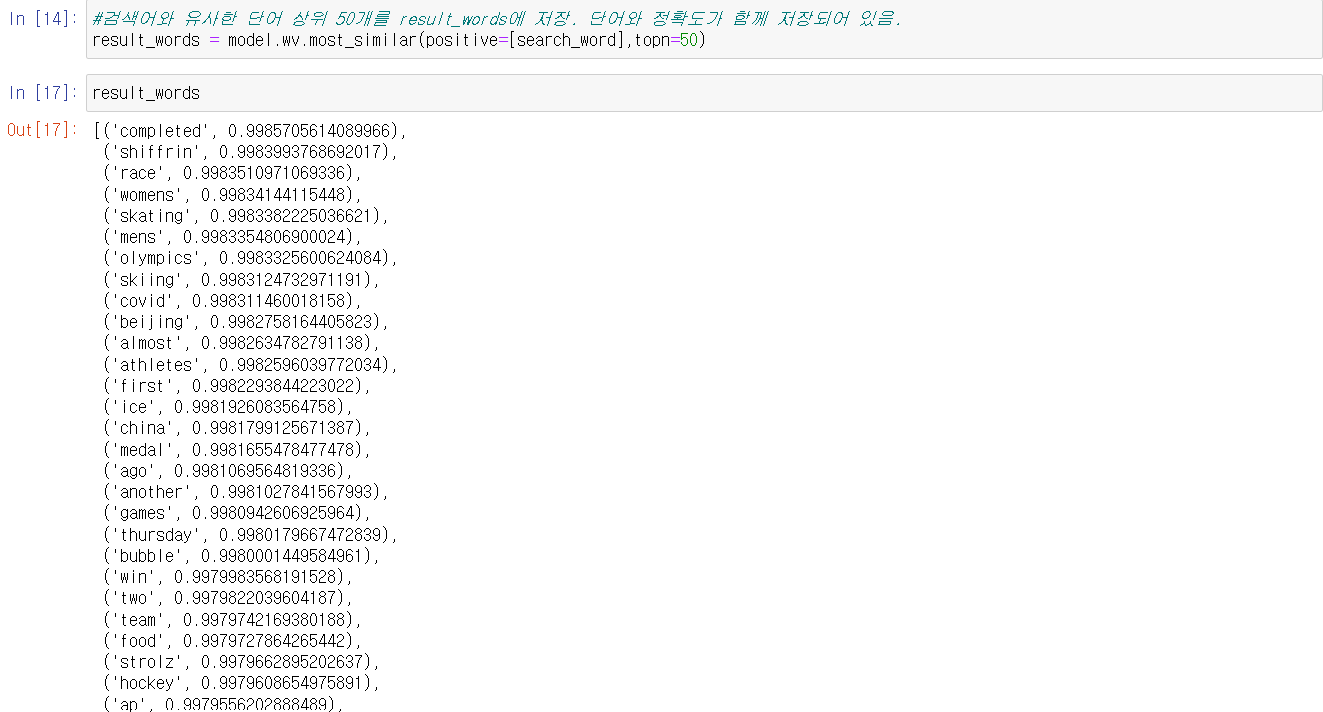
학습된 모델을 이용하여 처음 입력된 단어와 유사한 단어를 50개 가져온다. 정확도를 기준으로 상위 50개를 가져오게 된다.

정확도가 함께 보이던 것을 단어만 보이도록 정리해준다.
'MI Lab > Word2Vec - 2021.11~2022.01' 카테고리의 다른 글
| [단어 연관도 - Lab meeting] Tensorflow Lite - 2022.01.25.화 (0) | 2022.01.25 |
|---|---|
| [단어 연관도 - Lab meeting] 동시 출현 기반 - 2022.01.20.목 (0) | 2022.01.25 |
| [단어 연관도 - Lab meeting] word2vec 활용 - 2022.01.11.화 (0) | 2022.01.25 |
| [단어 연관도 - Lab meeting] word2vec 학습 데이터 - 2022.01.04.화 (0) | 2022.01.04 |
| [단어 연관도 분석] gensim 설치 (0) | 2022.01.03 |